Machine learning/deep learning/reinforcement learning/other AI projects with a focus on AI safety, including both technical research projects and some community resources for helping others learn.
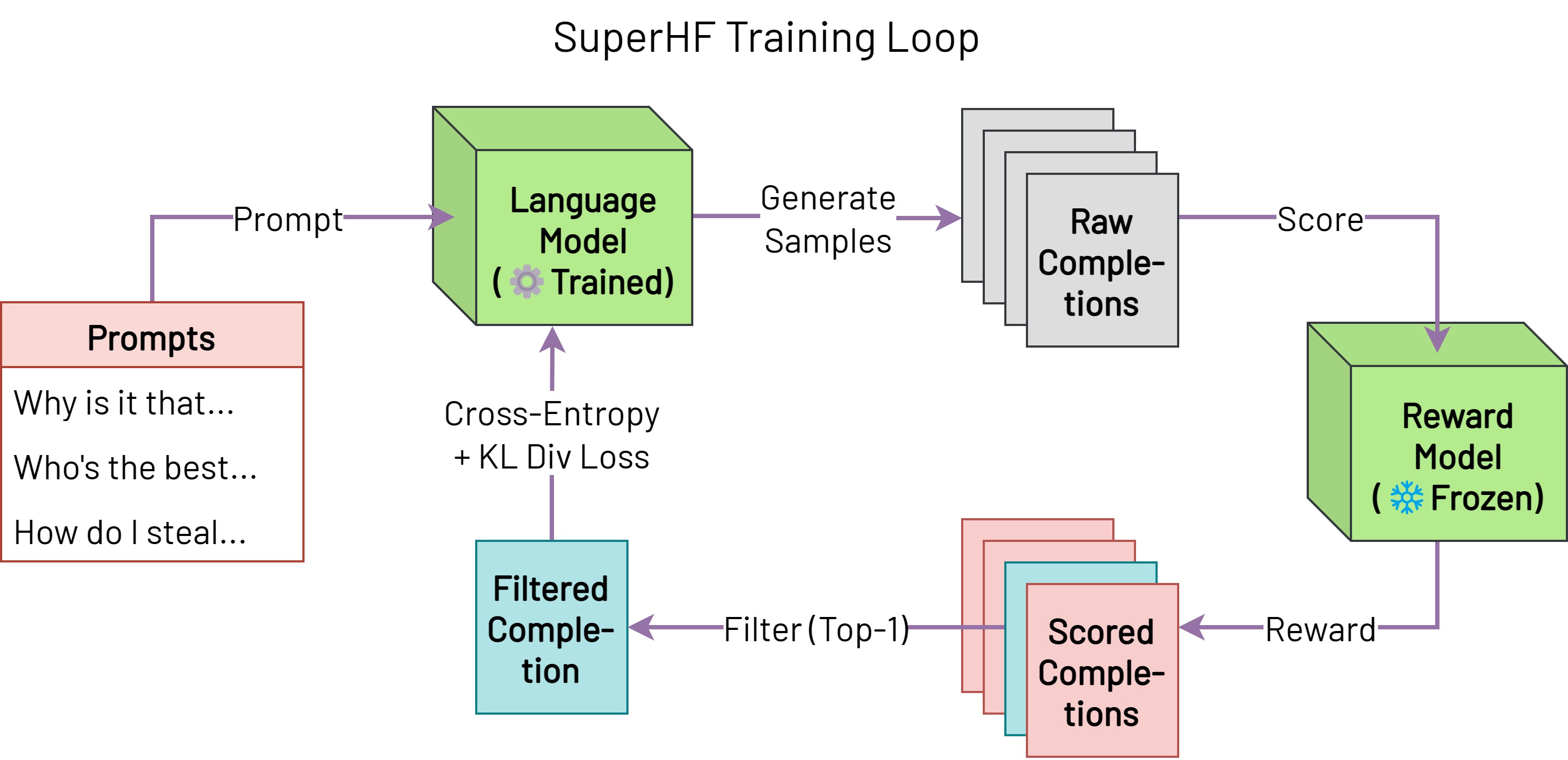
In-progress research project to develop alternatives to reinforcement learning from human feedback (RLHF) which use supervised learning instead of PPO-based RL to not change general capabilities while leading to better downstream safety performance. Responsible for: Co-leading the branch of the project focused on developing Supervised Iterative Learning from Human Feedback (SuperHF).
Simulated Comments from the Alignment Forum For Original Literature Development (SCAFFOLD) is a writing tool that generates comments that are similar to those on the Alignment Forum in order to elevate your AI safety to the next level! Responsible for: Everything sans data collection scripts.
An automated Sandwiching experimental framework for evaluating scalable oversight techniques by having language models talk to each other. We won 1st place in all categories at Apart Research's Scale Oversight Hackathon. Responsible for: Generating the initial research question and contributing roughly half of the theoretical development, the Python implementation, and the paper writeup.
Some quick and dirty mechanistic interpretability research into backup name mover heads for indirect object identification (IOI) in GPT-2 small, which won 2nd place in Apart Research's second Interpretability Hackathon. Responsible for: Deciding on the research question, engineering and running the mean ablation experiments, evaluating and interpreting results.
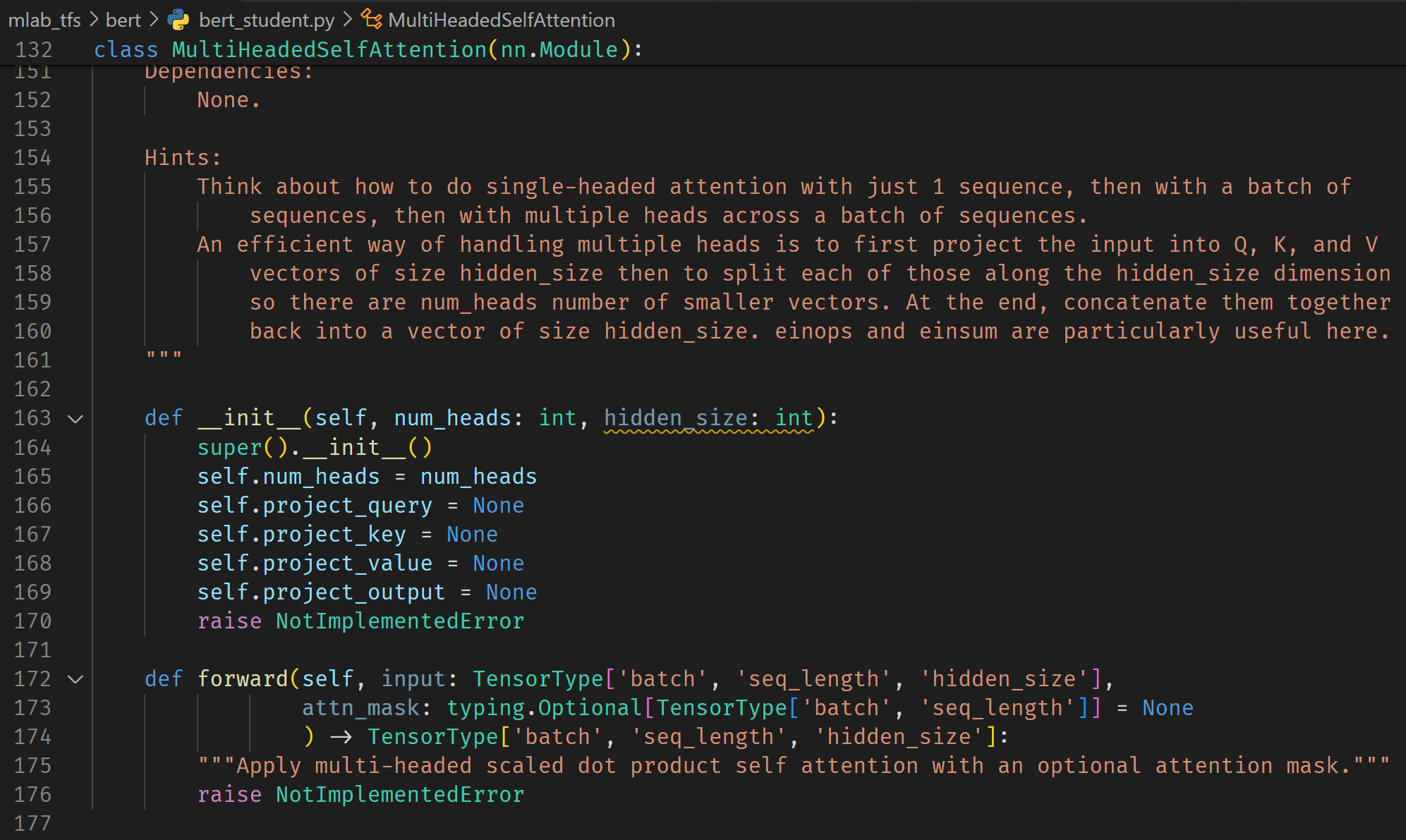
A documented and unit-tested repo to help you learn how to build transformer neural network models from scratch. Responsible for: Taking the transformer days from the original MLAB repo, creating a clean starter file with class/method stubs and clear docstrings, adding unit tests, and implementing a clean solution file.
A slightly new technique building off prior work for unsupervised learning of human-interpretable concept-based explanations of language models operating on the task of sentiment analysis. Compared to black-box baseline models, performance is comparable, but the coherency of discovered concepts is sometimes mixed. Responsible for: Almost all of the code, most of the paper.
A level-based guide for independently up-skilling in AI Safety Research Engineering that aims to give concrete objectives, goals, and resources to help anyone go from zero to hero. Responsible for: Everything, though it draws upon knowledge from others listed in the Sources section.
Evaluating the 2-digit multiplication abilities of various language models using 🤗Transformers and the OpenAI API for fun and to possibly inspire some mechanistic interpretability research. By graphing more nuanced metrics than accuracy like the number of digits different from the answer, we can see clearer patters in emergent multiplication capabilities. Responsible for: Everything.
While implementing Minitorch, a Python implementation of the core functionality of the popular PyTorch machine learning library, and getting a better understanding of how autodifferentiation, tensors, and other PyTorchic things work, I created this study guide to help others learn as well. Responsible for: All of the study guide, none of Minitorch.
A plugin to facilitate the use deep reinforcement learning in Unreal Engine by exposing UE4 as an OpenAI Gym environment and a suite of Deep RL samples project to test the plugin. Responsible for: Cleaning up and improving the plugin for release, creating all the sample projects while working for Epic Games.
A binary CNN classifier to distinguish between real photographic images and photorealistic computer-generated images that achieves 96% test accuracy on a custom dataset. Responsible for: Approximately half of the work.